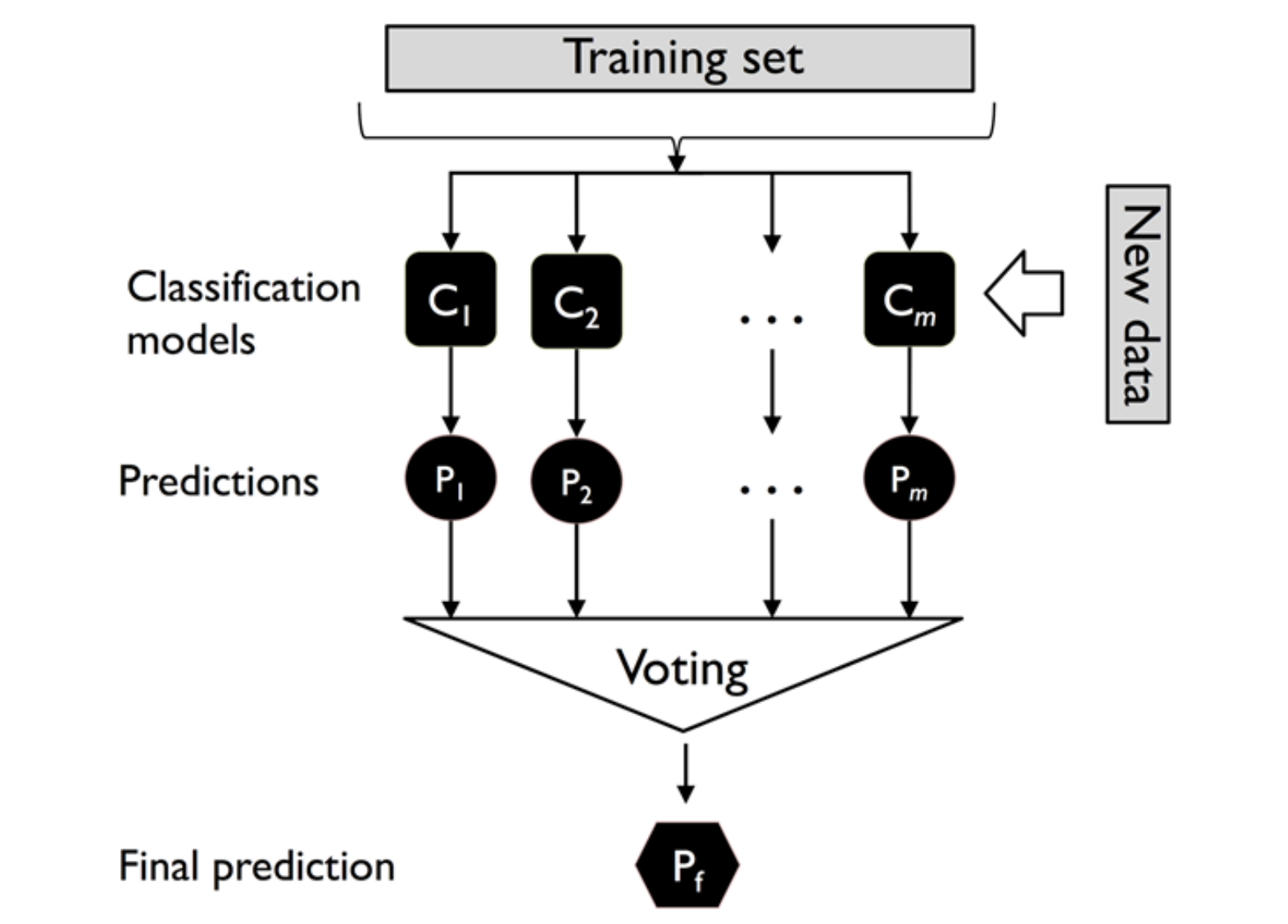
Plurality Majority Voting
多个模型分别输出预测结果,然后取投票最多的那个标签作为最后的输出。
用数学语言描述就是
y ^ = m o d e l { C i ( x ) } , 1 ≤ i ≤ m
\hat y=model\Big\{ C_i(x) \Big\},1\le i\le m
y ^ = m o d e l { C i ( x ) } , 1 ≤ i ≤ m 其中 C i C_i C i i i i
考虑训练了 2 n + 1 2n+1 2 n + 1 r r r
∑ k = n + 1 2 n + 1 ( k n ) r k ( 1 − r ) 2 n + 1 − k
\sum_{k=n+1}^{2n+1} \binom{k}{n}r^k(1-r)^{2n+1-k}
k = n + 1 ∑ 2 n + 1 ( n k ) r k ( 1 − r ) 2 n + 1 − k 当 n = 5 , r = 0.7 n=5,r=0.7 n = 5 , r = 0.7 0.9218 0.9218 0.9218
在此基础上,给每一个模型的预测结果添加权重
y ^ = arg max i ∈ A ∑ j = 1 m w j [ C j ( x ) = i ]
\hat y=\argmax_{i\in A} \sum_{j=1}^m w_j \Big[ C_j(\bold{x})=i \Big]
y ^ = i ∈ A arg max j = 1 ∑ m w j [ C j ( x ) = i ] 其中 A A A j j j x \bold x x i i i 1 1 1 0 0 0
因此,Weighted Vote 就相当于是枚举标签,然后看每一个模型预测结果的加权平均,取均值最大的那个对应的标签。
有的模型可以输出概率,所以我们也可以对概率进行加权,最后取最高
y ^ = arg max i ∈ A ∑ j = 1 m w j ⋅ P j ( i )
\hat y=\argmax_{i\in A}\sum_{j=1}^m w_j\cdot P_{j}(i)
y ^ = i ∈ A arg max j = 1 ∑ m w j ⋅ P j ( i ) 下面的代码实现了一个 Majority Vote Classifier (vote='classlabel') 和 Soft Vote (vote='probability')
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 from sklearn.base import BaseEstimator, ClassifierMixin, clonefrom sklearn.preprocessing import LabelEncoderfrom sklearn.pipeline import _name_estimatorsimport numpy as npimport operatorclass MajorityVoteClassifier (BaseEstimator, ClassifierMixin): def __init__ (self, classifiers, vote="classlabel" , weights=None ): ''' __init__ 函数接收分类器列表,进行初始化 vote 表示投票方法 ''' self .classifiers = classifiers self .named_classifiers = { key: value for key, value in _name_estimators(classifiers) } self .vote = vote self .weights = weights def fit (self, X, y ): ''' fit() 根据输入的数据 + 标签, 对标签进行 encoding(方便 Soft Vote 获取概率) 然后对 classifier 模型进行训练,并存起来 ''' self .label_enc = LabelEncoder() self .label_enc.fit(y) self .classes = self .label_enc.classes_ self .trained_classifiers = [] for classifier in self .classifiers: trained_clf = clone(classifier).fit( X, self .label_enc.transform(y), ) self .trained_classifiers.append(trained_clf) return self def predict (self, X ): ''' probability 部分比较容易理解 classlabel 部分的话,我们首先获取每一个模型的输出结果(`predictions`), 然后 ''' if self .vote == 'probability' : maj_vote = np.argmax(self .predict_proba(X), axis=1 ) else : predictions = np.asarray( [ clf.predict(X) for clf in self .trained_classifiers ] ).T maj_vote = np.apply_along_axis( lambda x: np.argmax(np.bincount(x, weights=self .weights)), axis=1 , arr=predictions) maj_vote = self .label_enc.inverse_transform(maj_vote) return maj_vote def predict_proba (self, X ): probas = np.asarray([clf.predict_proba(X) for clf in self .classifiers_]) avg_proba = np.average(probas, axis=0 , weights=self .weights) return avg_proba