
Particle Filter: Overview
现实世界里,
我们通过对这些点进行追踪,从而得到大致的分布。粒子的平均值代表对 state 的近似,粒子的分布代表对 state distribution 的近似
HMM view of PF
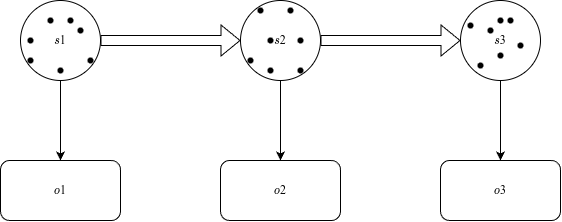
对于粒子滤波而言有这么几个东西比较重要:
粒子滤波算法流程
粒子滤波的流程大致可以分为这么几步
- 获得 observation
,得到每一个粒子对真实 state 的近似程度 - 对粒子进行重采样 (resample),越近似的粒子比重越大。重采样将近似程度低的粒子替换为近似程度高的粒子
- sample:对每一个粒子进行状态转移,即