
强化学习研究的是什么?
强化学习的研究目标可以概括为一句话:在特定的环境 (Environment) 下,智能体 (Agent) 如何通过和环境的交互,学习一个策略 (Policy),使其在长期内获得最大的累计奖励。
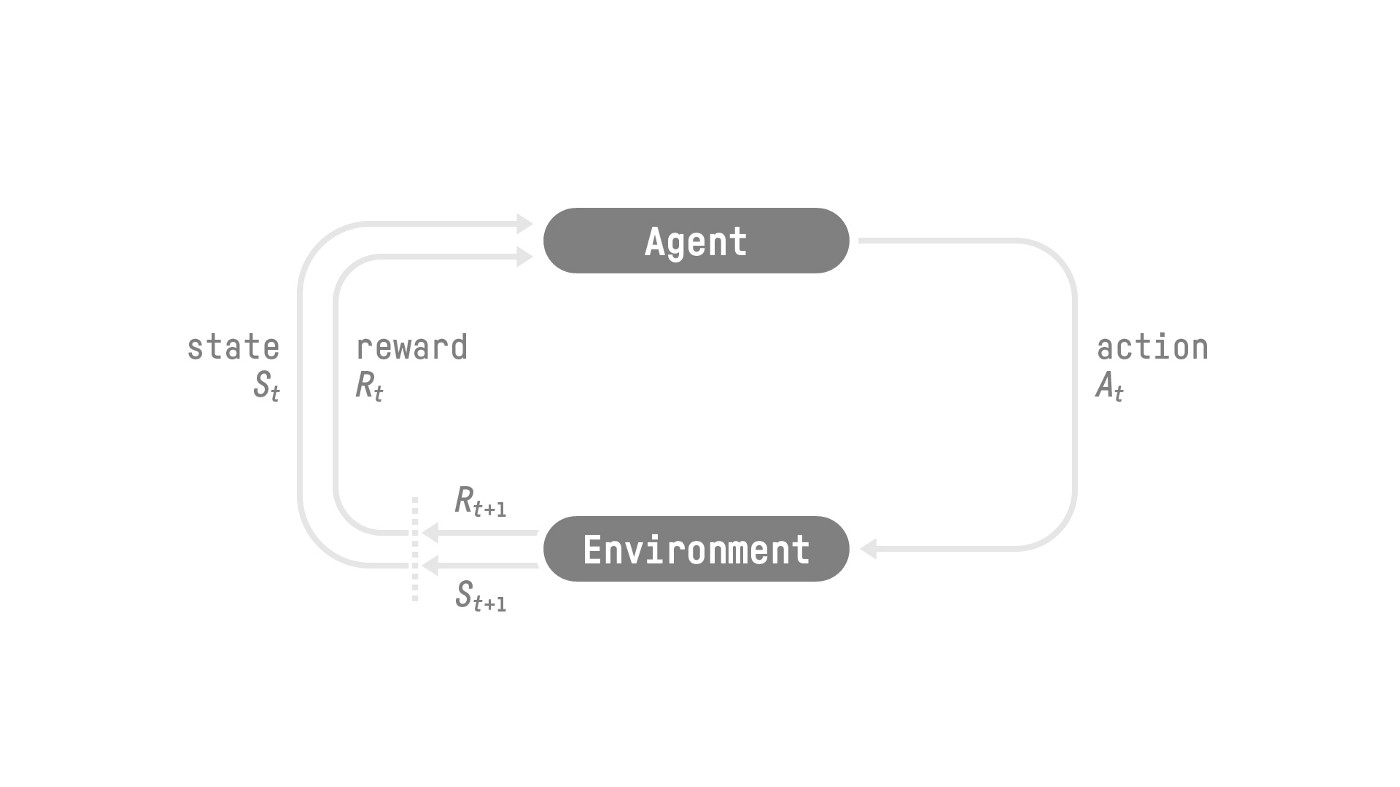
因此,从环境的视角来看,agent 实际上不断地在产生 State, Action, State, Action, … 的数据:agent 每一次行动都会导致自己的 state 发生变化。
agent 通过和环境的交互学习如何根据环境和状态决定自己下一步的动作,也就是 policy. 我们可以把 policy 看成是一个函数:接收当前 state 作为参数,输出 action 表示当前 state 下应该怎么行动
那么我们怎么让 agent 学习 action 呢?如果我们希望 agent 按照我们预想的那样,在特定的 state 下学习到应该走出特定的步骤,我们该怎么诱导 agent 呢?就是利用 Reward 机制,诱导 agent 向着 Reward 更大的方向行动,就好像我们玩游戏的时候也是朝着让自己更加“强大”的方向去打怪升级。
于是我们就需要给 agent 的每一次行动进行“打分”,告诉 agent 你这一步棋走的好不好。我们可以把 Reward 也看成一个函数,给定
于是考虑上 reward 的话,agent 的动作 sequence 就变成了
传统强化学习算法: Deterministic Approach
传统强化学习算法简而言之就是