图像生成模型的本质是一个概率模型 :如果我们知道了真实图像 x x x p ( x ) p(x) p ( x ) x ′ ∼ p ( x ) x'\sim p(x) x ′ ∼ p ( x ) x ′ x' x ′
不过通常,p ( x ) p(x) p ( x )
先生成图片的特征 ,例如想要生成二次元图片,就先指定 tags 例如发色、动作等等
在根据特征,去生成图像
我们用 z z z latent variable ),那么这样的过程就是如同下面所示
z ⟶ guide x
\boxed{z}\overset{\text{guide}}{\longrightarrow} \boxed{x}
z ⟶ guide x 用数学语言描述就是这样一个恒等式
p ( x ) = ∑ z p ( x ∣ z ) ⋅ p ( z )
p(x)=\sum_z p(x|z)\cdot p(z)
p ( x ) = z ∑ p ( x ∣ z ) ⋅ p ( z ) VAE 的推理从数学的角度也就变成了
Sample z z z p ( z ) p(z) p ( z )
Sample x x x p ( x ∣ z ) p(x|z) p ( x ∣ z )
当然,由于我们的目的是简化 p ( x ) p(x) p ( x )
p ( z ) ∼ N ( 0 , 1 ) p ( x ∣ z ) ∼ N ( μ θ ( z ) , Σ θ ( z ) )
\begin{aligned}
p(z)&\sim \mathcal N(0,1)\\
p(x|z)&\sim \mathcal N(\mu_\theta(z),\Sigma_\theta(z))
\end{aligned}
p ( z ) p ( x ∣ z ) ∼ N ( 0 , 1 ) ∼ N ( μ θ ( z ) , Σ θ ( z )) 其中 μ θ ( ⋅ ) , Σ θ ( ⋅ ) \mu_\theta(\cdot),\Sigma_\theta(\cdot) μ θ ( ⋅ ) , Σ θ ( ⋅ )
这里也不一定非得是正态分布,其他容易计算的分布也可以。简单起见直接用正态分布了
给定一个数据集 D = { x 1 , x 2 , … , x m } \mathcal D=\{x^{1}, x^{2}, \dots, x^{m}\} D = { x 1 , x 2 , … , x m } D \mathcal D D p θ ( x ) p_\theta(x) p θ ( x ) p ( x ) p(x) p ( x ) KL 散度 ,即训练目标为最小化 KL 散度:
min θ D K L ( p θ ( x ) ∥ p ( x ) )
\min_\theta D_{KL}\Big( p_\theta(x) \big\| p(x) \Big)
θ min D K L ( p θ ( x ) p ( x ) ) 最小化 KL 散度等同于最大化 Marginal Log-Likelilhood log p θ ( x ) \log p_\theta(x) log p θ ( x ) D \mathcal D D
max θ ∑ x i ∈ D log p θ ( x i ) = max θ ∑ x i ∈ D log ( ∑ z p θ ( x i , z ) )
\begin{aligned}
&\max_\theta \sum_{x^{i} \in\mathcal D} \log p_\theta(x^{i})\\
=&\max_\theta \sum_{x^{i} \in\mathcal D} \log \Big(\sum_z p_\theta(x^{i},z)\Big)
\end{aligned}
= θ max x i ∈ D ∑ log p θ ( x i ) θ max x i ∈ D ∑ log ( z ∑ p θ ( x i , z ) ) 然而,z z z ∑ z \sum_z ∑ z z z z p θ ( x i , z ) p_\theta(x^{i},z) p θ ( x i , z ) 近似求解 log-likelihood
我们随机采样一些 z i ∼ p ( z ) z^{i} \sim p(z) z i ∼ p ( z ) z i z^{i} z i
log p θ ( x ) ≈ log 1 k ∑ i = 1 k p ( x ∣ z i ) , z i ∼ p ( z )
\log p_\theta(x)\approx \log \frac{1}{k}\sum_{i=1}^k p(x|z^{i}), \quad z^{i}\sim p(z)
log p θ ( x ) ≈ log k 1 i = 1 ∑ k p ( x ∣ z i ) , z i ∼ p ( z ) 尽管理论上,蒙特卡洛估计方法是 no-bias 的,但是在实战中,用蒙特卡洛计算出来的梯度具有很大的方差。
比起直接 maximize 目标,我们也可以构造出目标的 lower bound 然后通过 maximize 这个 lower bound 从而 maximize 目标。
此处,log p θ ( x ) \log p_\theta(x) log p θ ( x ) ELBO (Evidence Lower Bound)
p θ ( x ) = ∑ z q ( z ) q ( z ) p θ ( x , z ) = ∑ z q ( z ) ⋅ p θ ( x , z ) q ( z ) = E z ∼ q ( z ) [ p θ ( x , z ) q ( z ) ] log p θ ( x ) = log E z ∼ q ( z ) [ p θ ( x , z ) q ( z ) ] = log ∑ z q ( z ) ⋅ p θ ( x , z ) q ( z ) ≥ ∑ z q ( z ) ⋅ log p θ ( x , z ) q ( z ) ‾ by Jensen’s Inequality = E z ∼ q ( z ) [ log p θ ( x , z ) q ( z ) ] ≔ ELBO ( x ; θ ) = L θ ( x )
\begin{aligned}
p_\theta(x)
&=\sum_z \frac{q(z)}{q(z)}p_\theta(x,z)\\
&=\sum_z q(z)\cdot \frac{p_\theta(x,z)}{q(z)}\\
&=\mathbb E_{z\sim q(z)}\Big[\frac{p_\theta(x,z)}{q(z)}\Big]\\
\log p_\theta(x)&=\log \mathbb E_{z\sim q(z)}\Big[ \frac{p_\theta(x,z)}{q(z)} \Big]\\
&= \log \sum_z q(z)\cdot \frac{p_\theta(x,z)}{q(z)}\\
&\ge \underset{\scriptsize\text{by Jensen's Inequality}}{\underline{\sum_z q(z)\cdot \log\frac{p_\theta(x,z)}{q(z)}}}\\
&=\mathbb E_{z\sim q(z)}\Big[ \log\frac{p_\theta(x,z)}{q(z)} \Big]\\
&\coloneqq \text{ELBO}(x;\theta)=\mathcal L_{\theta}(x)
\end{aligned}
p θ ( x ) log p θ ( x ) = z ∑ q ( z ) q ( z ) p θ ( x , z ) = z ∑ q ( z ) ⋅ q ( z ) p θ ( x , z ) = E z ∼ q ( z ) [ q ( z ) p θ ( x , z ) ] = log E z ∼ q ( z ) [ q ( z ) p θ ( x , z ) ] = log z ∑ q ( z ) ⋅ q ( z ) p θ ( x , z ) ≥ by Jensen’s Inequality z ∑ q ( z ) ⋅ log q ( z ) p θ ( x , z ) = E z ∼ q ( z ) [ log q ( z ) p θ ( x , z ) ] : = ELBO ( x ; θ ) = L θ ( x )
而实际上
log p θ ( x ) = E z ∼ q ( z ) [ log p θ ( x , z ) ] + H ( q ) entropy of q ( z ) ‾
\log p_\theta(x)=\mathbb E_{z\sim q(z)}\Big[ \log p_\theta(x,z) \Big] + \underset{\overline{\scriptsize\text{entropy of }q(z)}}{H(q)}
log p θ ( x ) = E z ∼ q ( z ) [ log p θ ( x , z ) ] + entropy of q ( z ) H ( q ) 直觉上理解,我们选取的 q ( z ) q(z) q ( z )
D K L ( q ( z ) ∥ p θ ( z ∣ x ) ) D_{KL}\Big( q(z) \big\| p_\theta(z|x) \Big) D K L ( q ( z ) p θ ( z ∣ x ) ) 越小越好。而 D K L ( ) D_{KL}() D K L ( )
log p θ ( x ) = ELBO + D K L ( q ( z ) ∥ p θ ( z ∣ x ) )
\log p_\theta(x)=\text{ELBO}+D_{KL}\Big( q(z)\big\|p_\theta(z|x) \Big)
log p θ ( x ) = ELBO + D K L ( q ( z ) p θ ( z ∣ x ) )
然后我们就又可以用 Monte Carlo 方法估计 ELBO 了。
ELBO ( x ; θ ) ≈ 1 k ∑ i = 1 k log p θ ( x , z i ) q ( z i ) , z i ∼ q ( z )
\text{ELBO}(x;\theta)\approx \frac{1}{k}\sum_{i=1}^k \log\frac{p_\theta(x,z^{i})}{q(z^{i})},\quad z^{i}\sim q(z)
ELBO ( x ; θ ) ≈ k 1 i = 1 ∑ k log q ( z i ) p θ ( x , z i ) , z i ∼ q ( z ) 到目前位置,我们实际上只讨论了 Decoder 部分:p θ ( x ∣ z ) p_\theta(x|z) p θ ( x ∣ z ) x → z x\to z x → z
Encoder 负责的就是 p θ ( z ∣ x ) p_\theta(z|x) p θ ( z ∣ x ) p θ ( z ∣ x ) p_\theta(z|x) p θ ( z ∣ x ) D K L ( q ( z ) ∥ p θ ( z ∣ x ) ) D_{KL}\Big( q(z)\big\| p_\theta(z|x) \Big) D K L ( q ( z ) p θ ( z ∣ x ) ) q ( z ) q(z) q ( z ) p θ ( z ∣ x ) p_\theta(z|x) p θ ( z ∣ x )
所以,我们把 q ( z ) q(z) q ( z ) q ϕ ( z ) q_\phi(z) q ϕ ( z ) ϕ \phi ϕ
ELBO = L θ , ϕ ( x ) = ∑ z q ϕ ( z ) log p θ ( z , x ) + H ( q ϕ ( z ) )
\text{ELBO}=\mathcal L_{\theta,\phi}(x)=\sum_z q_\phi(z)\log p_\theta(z,x)+H(q_\phi(z))
ELBO = L θ , ϕ ( x ) = z ∑ q ϕ ( z ) log p θ ( z , x ) + H ( q ϕ ( z )) 注意:这里的 Decoder 与 Encoder 本质上是对分布进行建模 ,即给定张量,输出一个分布 。
如果 Encoder 部分我们为每一个输入的图像都训练一个 Encoder q ϕ ( z ) q_\phi(z) q ϕ ( z )
因此,我们用神经网络对分布进行拟合,即 g λ : x i ↦ q ϕ i ( z ) g_\lambda:x^{i} \mapsto q_{\phi^{i}}(z) g λ : x i ↦ q ϕ i ( z ) ϕ i \phi^{i} ϕ i
而对 Decoder 部分就不用了,因为 p θ ( x ∣ z ) p_\theta(x|z) p θ ( x ∣ z ) z z z q ϕ ( z ) ≈ p θ ( z ∣ x ) q_\phi(z)\approx p_\theta(z|x) q ϕ ( z ) ≈ p θ ( z ∣ x )
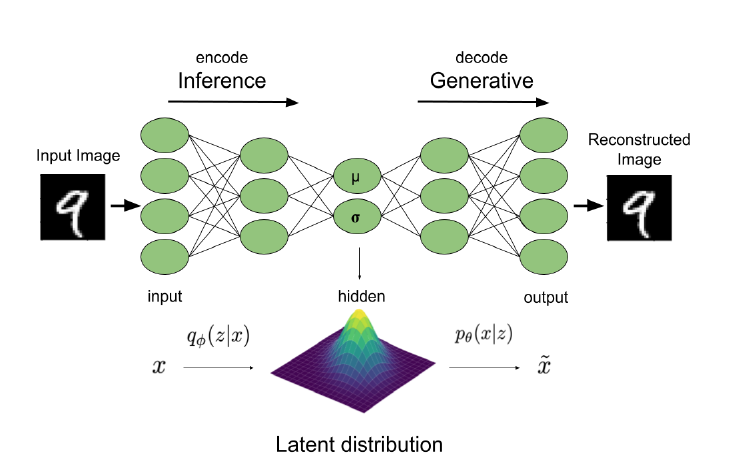
VAE 有一个 Encoder 架构,负责将图像 x x x z z z z z z x x x
上文的 ELBO 则为我们优化 VAE 模型提供了一个良好的目标函数:(其实应该是求解上文的 λ \lambda λ
max θ , ϕ ELBO = max θ ∑ x ∈ D max ϕ E q ϕ ( z ) [ log p θ ( z , x ) q ϕ ( z ) ] ⇒ max θ , λ ∑ x ∈ D max λ E g λ ( x ) [ log p θ ( z , x ) g λ ( x ) ]
\begin{aligned}
\max_{\theta,\phi}\text{ELBO}&=\max_{\theta}\sum_{x\in\mathcal D}\max_{\phi}\mathbb E_{q_\phi(z)}\Bigg[ \log\frac{p_\theta(z,x)}{q_\phi(z)} \Bigg]\\
&\Rightarrow\max_{\theta,\lambda}\sum_{x\in\mathcal D}\max_\lambda\mathbb E_{g_\lambda(x)}\Bigg[ \log\frac{p_\theta(z,x)}{g_\lambda(x)} \Bigg]
\end{aligned}
θ , ϕ max ELBO = θ max x ∈ D ∑ ϕ max E q ϕ ( z ) [ log q ϕ ( z ) p θ ( z , x ) ] ⇒ θ , λ max x ∈ D ∑ λ max E g λ ( x ) [ log g λ ( x ) p θ ( z , x ) ] 用随机梯度下降法进行学习
初始化 θ , ϕ 1 … m \theta,\phi^{1\dots m} θ , ϕ 1 … m
随机一个 x i ∈ D x^{i} \in\mathcal D x i ∈ D
先优化 ϕ i \phi^{i} ϕ i
ϕ i ← ϕ i + η ∇ ϕ i L θ , ϕ ( x i ) \phi^{i}\gets \phi^{i}+\eta \nabla_{\phi^{i}}\mathcal L_{\theta,\phi}(x^{i}) ϕ i ← ϕ i + η ∇ ϕ i L θ , ϕ ( x i ) 直到收敛为止
更新 θ \theta θ θ ← θ + η ∇ θ L θ , ϕ i ( x i ) \theta\gets\theta+\eta\nabla_{\theta}\mathcal L_{\theta,\phi^{i}}(x^{i}) θ ← θ + η ∇ θ L θ , ϕ i ( x i )
那么我们如何计算梯度呢?因为很有可能这个式子并不存在 closed form,我们依然采用 Monte Carlo 的方法解决问题,即
E q ϕ ( z ) [ log p θ ( z , x ) − log q ϕ ( z ) ] ≈ 1 K ∑ i = 1 K log p θ ( z i , x ) − log q ϕ ( z i )
\mathbb E_{q_\phi(z)}\Bigg[ \log p_\theta(z,x)-\log q_\phi(z) \Bigg]\approx \frac{1}{K}\sum_{i=1}^{K}\log p_\theta(z^{i},x)-\log q_\phi(z^{i})
E q ϕ ( z ) [ log p θ ( z , x ) − log q ϕ ( z ) ] ≈ K 1 i = 1 ∑ K log p θ ( z i , x ) − log q ϕ ( z i ) 其中 q ϕ ( z ) q_\phi(z) q ϕ ( z ) θ \theta θ
∇ θ E q ϕ ( z ) [ log p θ ( z , x ) − log q ϕ ( z ) ] ≈ 1 K ∑ i = 1 K ∇ θ log p θ ( z i , x )
\nabla_\theta \mathbb E_{q_\phi(z)}\Bigg[ \log p_\theta(z,x)-\log q_\phi(z) \Bigg]\approx \frac{1}{K}\sum_{i=1}^K \nabla_\theta \log p_\theta(z^{i},x)
∇ θ E q ϕ ( z ) [ log p θ ( z , x ) − log q ϕ ( z ) ] ≈ K 1 i = 1 ∑ K ∇ θ log p θ ( z i , x ) 然而 ELBO 关于 ϕ i \phi^i ϕ i
我们把 q ϕ ( z ) ∼ N ( μ , σ 2 I ) q_\phi(z)\sim \mathcal N(\mu, \sigma^2 I) q ϕ ( z ) ∼ N ( μ , σ 2 I ) ϕ i = ( μ , σ ) \phi^i=(\mu,\sigma) ϕ i = ( μ , σ )
ϵ ∼ N ( 0 , 1 ) z = μ + σ ϵ = g ϕ ( ϵ )
\epsilon\sim \mathcal N(0,1)\\
z=\mu+\sigma\epsilon=g_\phi(\epsilon)
ϵ ∼ N ( 0 , 1 ) z = μ + σ ϵ = g ϕ ( ϵ ) 借用这个想法,我们可以改写 ELBO,这里先让 r ( z ) = log q ϕ ( z ) r(z)=\log q_\phi(z) r ( z ) = log q ϕ ( z )
E z ∼ q ϕ ( z ) [ r ( z ) ] = ∑ z q ϕ ( z ) r ( z ) = E ϵ ∼ N ( 0 , 1 ) [ r ( g ϕ ( ϵ ) ) ] = ∫ N ( ϵ ) r ( μ + σ ϵ ) d ϵ ∇ ϕ E q ϕ ( z ) [ r ( z ) ] = ∇ ϕ E ϵ [ r ( g ϕ ( ϵ ) ) ] = E ϵ [ ∇ ϕ r ( g ϕ ( ϵ ) ) ] ≈ 1 K ∑ i = 1 K r ( g ϕ ( ϵ i ) ) ‾ Monte Carlo Estim
\begin{aligned}
\mathbb E_{z\sim q_\phi(z)}[r(z)]&=\sum_z q_\phi(z)r(z)\\
&=\mathbb E_{\epsilon\sim\mathcal N(0,1)}[r(g_\phi(\epsilon))]\\
&=\int \mathcal N(\epsilon) r(\mu+\sigma\epsilon) d\epsilon\\
\nabla_\phi \mathbb E_{q_\phi(z)}[r(z)]&=\nabla_\phi \mathbb E_\epsilon [r(g_\phi(\epsilon))]\\
&=\mathbb E_{\epsilon}[\nabla_\phi r(g_\phi(\epsilon))]\\
&\approx \underset{\text{Monte Carlo Estim}}{\underline{\frac{1}{K}\sum_{i=1}^K r(g_\phi(\epsilon^i))}}
\end{aligned}
E z ∼ q ϕ ( z ) [ r ( z )] ∇ ϕ E q ϕ ( z ) [ r ( z )] = z ∑ q ϕ ( z ) r ( z ) = E ϵ ∼ N ( 0 , 1 ) [ r ( g ϕ ( ϵ ))] = ∫ N ( ϵ ) r ( μ + σ ϵ ) d ϵ = ∇ ϕ E ϵ [ r ( g ϕ ( ϵ ))] = E ϵ [ ∇ ϕ r ( g ϕ ( ϵ ))] ≈ Monte Carlo Estim K 1 i = 1 ∑ K r ( g ϕ ( ϵ i ))