MapReduce
The computation takes a set of input key/value pairs, and produces a set of output key/value pairs.
Map
Map, takes an input pair and produces a set of intermediate key/value pairs. The runtime system gather together all intermediate values associated with the same intermediate key and passes them to the Reduce function.
Reduce
The Reduce function, accepts an intermediate key and a set of values for that key. It merges together these values to form a possibly smaller set of values. Typically just zero or one output value is produced per Reduce invocation. The intermediate values are supplied to the user’s reduce function via an iterator. This allows handling lists of values that are too large to fit in memory.
Execution Overview
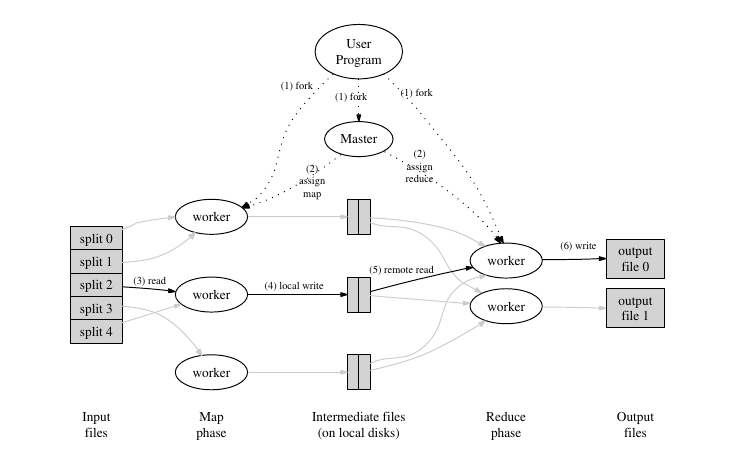
As described in the paper,
- The runtime system first splits the input files into pieces of typically MB per piece. Then, it starts many copies of the program on a cluster.
- One copy is special, the master. The rest are workers that are assigned work by the master. There are map tasks and reduce tasks. The master picks idle workers and assign each one with a map or reduce task.
- A worker who is assigned a map task read the contents of the corresponding input split. It parses input key-value pairs out of the input data and passes each pair to the user-defined Map function. The intermediate key-value pairs produced by the Map function are buffered in memory.
- Periodically, the buffered pairs are written to local disk, partitioned into regions by the partitioning function. The locations of these pairs on the disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
- When a reduce worker is notified by the master about these locations, it uses RPCs to read buffered data from local disks. On allocated locations, reduce workers sort these pairs by intermediate keys so that all occurrences of the same key are grouped together.
- The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encounter, it passes the key and corresponding set of intermediate values to the user’s Reduce function. The output of Reduce function is appended to a final output file for this reduce partition.
- When all map tasks and reduce tasks have been completed, the master wakes up the user program, and then returns back to the user code.
Master Node Design
The master keeps several data structures. For each map/reduce task, it stores the state (idle, in-progress or completed) and the identity of the worker machine for non-idle tasks.
For each completed map task, the master stores the location and sizes of the intermediate file regions produced by map tasks. The information is pushed incrementally to reduce workers that have in-progress reduce tasks.
Fault Tolerance
Worker Failure
The master sends heartbeat to every worker periodically. If no response is received, this worker is marked as failed.
Refinements
Partitioning Function
Suppose the number of reduce tasks/output files desired is , the default partitioning function is to use hashing, e.g. .