To embed positional information into token embeddings, we want the following property
fq(xm,m)⊤fk(xn,n)=g(xm,xn,m−n)
An idea that is used in vanilla positional embedding (in Attention paper) is to use angles to encode positional index, i.e. f′(mθ,nθ)=g′((m−n)θ). And we can use trigonometric functions.
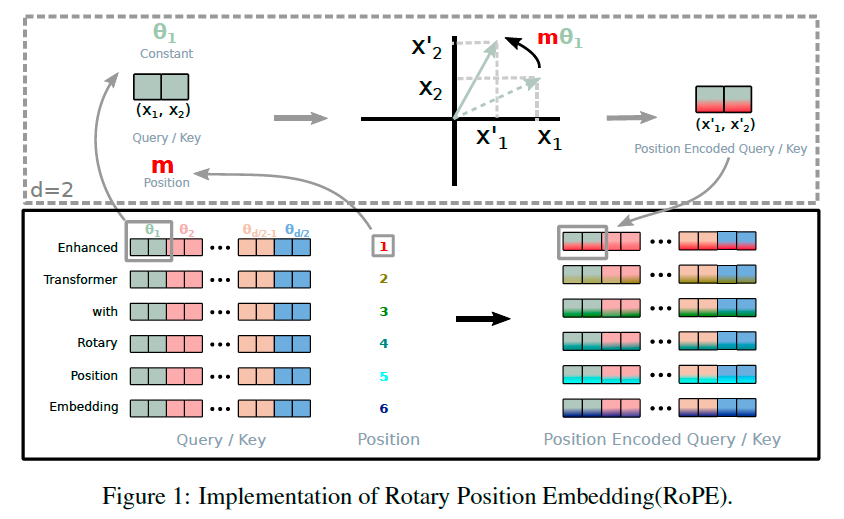
In cases that word embedding dimension is 2, i.e., d=2, we can use the 2D rotation matrix.
Rm=(cosmθsinmθ−sinmθcosmθ)
The rotation matrix satisfies that Rm⊤Rn=Rm−n, thus if we let
fq(xm,m)=RmWqxm,fk(xn,n)=RnWkxn
Then we have
fq⊤fk=(RmWqxm)⊤RnWkxn=(Wqxm)⊤Rm−n(Wkxn)
Thus, in the case that d is large and d is even, we can split d into d/2 pairs and apply the 2D case for each pair.
Note that for each pair, we have to assign a unique θi,i=1,2,…,d/2. But for d/2 pairs of the same token, they have same m value in the Rm matrix.
In practice, it’s not efficient to chunk adjacent elements. Instead, we usually split d elements into first half and second half which are all continuous.