Self attention is built on top of attention module, where matrices all come from the same input, but is multplied by different transformation matrices.
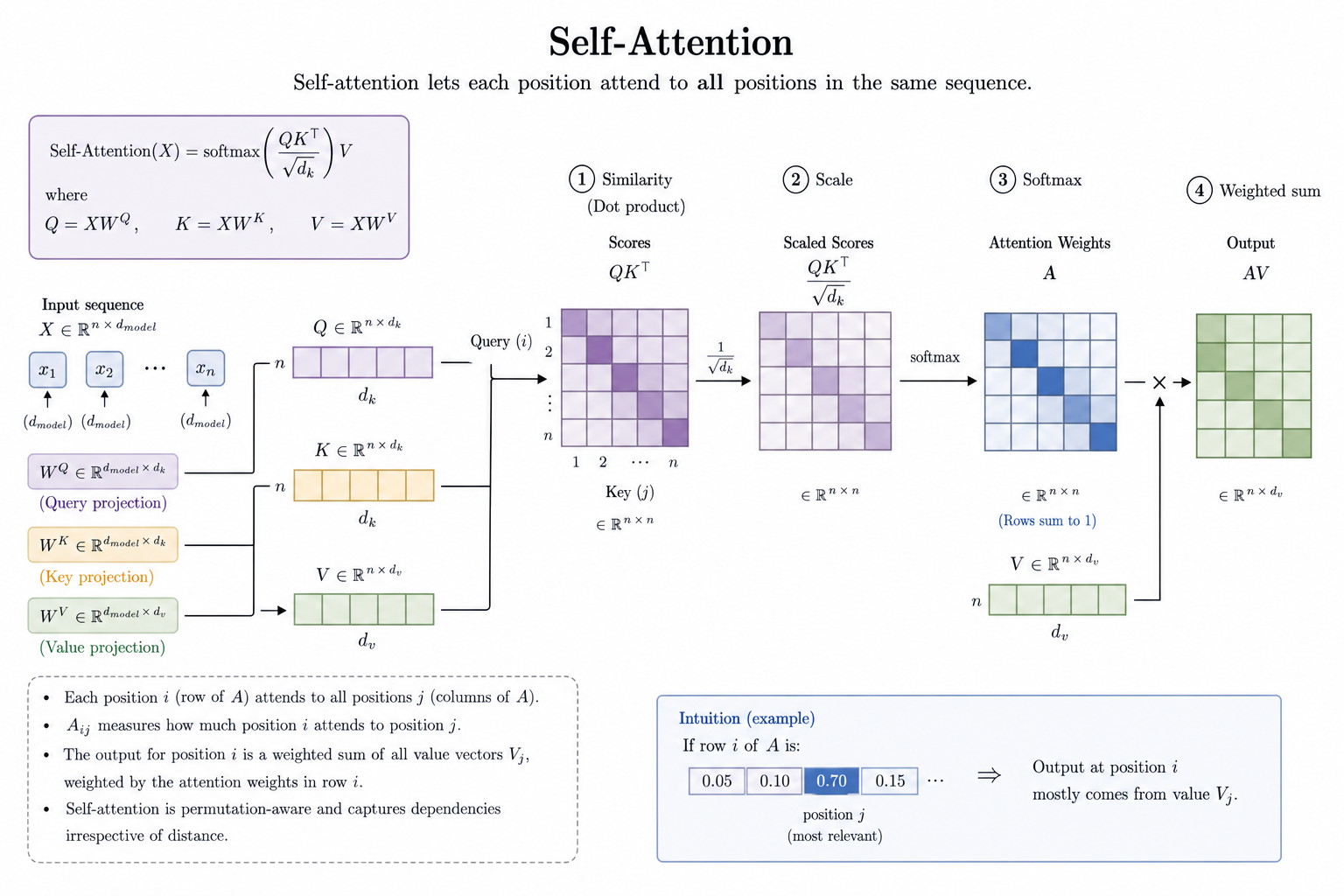
Suppose we have input sequence , which means a sequence of tokens with each token has an embedding dimension .
We then first transform into respectively with 3 matrices, and . Now that and , meaning that input sequence are projected into 2 “spaces” ( space and space).
Then the rest is same as naive attention:
- We first compute , then divided by , and then . The resulting matrix is a score matrix (attention weights) , where -th row represents the similarity between -th token and all the tokens in the sequence.
- We then compute to get “meaning interpolation” for each row (i.e., each token). The resulting matrix is encodes the “meaning” of each token (i.e., each row)