The idea of attention is simple. It’s like looking up in a dictionary. Suppose we want to look up for the meaning of acedfness, and we know the meaning of acedf. Then, we may assume that the meaning of acedfness has something to do with acedf.
And that’s the idea of attention mechanism. Given a token (word) under query , we have a dictionary of tokens , called keys, and vectors (which “encode” the meanings of tokens) , called values. We can interpret the query token with a linear interpolation of values, based on similarity between query and keys.
So the question becomes: how can we compute the similarity between tokens. First, the similarity must be related to similarity in meaning; second, since it’s linear interpolation, all weights should be accumulated to .
Previously, we use vectors to “encode” meanings of tokens for values. We can apply the same trick on queries and keys. And thus, in the famous paper “Attention is All You Need”, softmax() function along with cosine similarity between vectors to achieve the goal. We further extend cosine similarity to matmul to do the procedure for multiple queries at the same time. This gives the famous attention formula:
The Attention
The stands for the dimension of embedding i.e., the vectors mentioned in previous paragraphs.
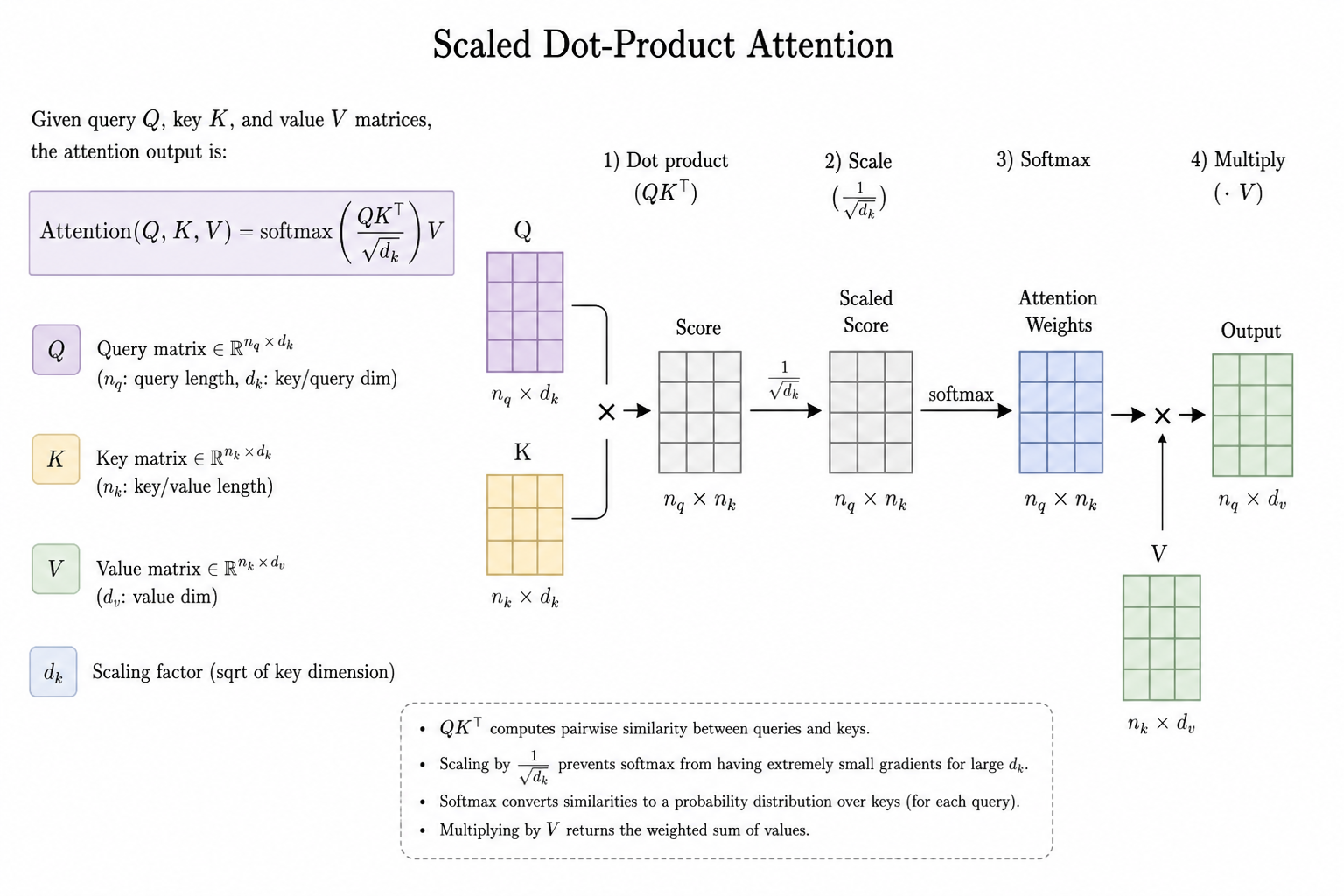
Why a on denominator? That’s because if we assume to both follow a distribution of , then their dot product with have a variance of , thus a denominator of reduces the variance to again.