Next-Token Prediction
Most LLMs choose a self-supervised learning method. The reason is that as long as we have retrieved data, no extra annotation is required, which greatly reduces human labour involvement. Among self-supervised learning method, 2 directions are potential options: 1) next-token prediction; 2) masked language modeling.
While some models like BERT uses the latter way, most LLMs nowadays uses next-token prediction. The reason is simple: through next-token prediction, we can unify different tasks with same representation.
Post-Training
Even after pre-training, LLMs are far from production, since they have just learned (conditioned) distribution of tokens (similar to basic knowledge), but lacks ability in downstream tasks, instruction following and safety, which has become the most important parts in real-world applications. e.g. for instruction following, we have to let LLM follow specific format (like outputting list when prompted “list 3 items”), role playing and multi-step tasks; and for safety, we want LLM to avoid bias, factual error and refuse harmful requests.
Supervised Fine-tuning (SFT)
Which is the most intuitive way. We just have to prepare relevant data and finetune. The difference between training and finetuning is just that finetuning usually requires less data and less epoches, and we usually have more parameter efficient methods for finetuning (PEFT).
SFT still faces challenges, mostly concerns on data. And we have developed reliable way to mitigate defects brought by these problems.
| Challenges | Explanation | Impact | Solution |
|---|---|---|---|
| Data Scarcity | not enough data (e.g. robotics) | limit model capacity | data augment/synthesis |
| Overfitting | reduce generalization | Training Regularization | |
| Catastrophic Forget | model become dumb | knowledge retention | |
| Data bias | templated responses | diversity assurance |
Reinforcement Learning
RL is adopted to align human preference and safety, which is a common approach used by OpenAI, Anthropic and Google. There’re 3 mainstream technology:
- RL with Human Feedback (RLHF)
- train Reward model with human feedback
- tune LLM with PPO/GRPO algorithm to compute reward.
In practice, RLHF best aligns with human preference. However, human anootation could be too expensive. So, we can train a reward model to automatically compute reward score, so as to automate the evaluation procedure.
Medieval Era of Agents: Exploring Boundary of LLM Ability
Emergent Ability
From now on, as LLM grow larger and larger, we find LLM have emergent abilities, that is to say, when LLM becomes large enough, they “magically” gains the ability to finish tasks well, even new tasks. The abilities cannot be predicted on smaller models.
Among these capabililties, we found three are most important, which unlocks the agent era:
- In-context learning. LLM can learn from examples in the input prompt without parameter update.
- Chain-of-Thought reasoning. Step-by-step reasoning before giving final answer.
- Instruction following. LLM can follow explicit commands and requests accurately.
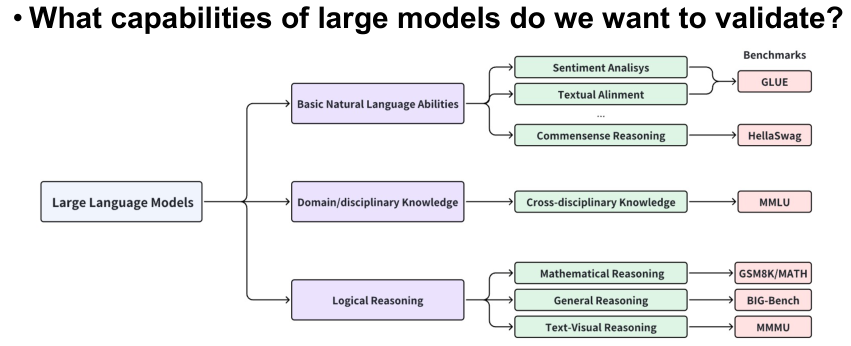
LLM Evaluation
To test out certain ability of LLM, of course we need to develop related metrics and benchmarks for quantitive evaluation. The following image is a brief summary of relevant topics.
Human or Automated Evaluation
This is a trade-off where one side being efficiency, reporducibility, scalability, while another side being depth, flexibility and authenticity.
In practice, we may use automated evaluation for large-scale screening and human evaluation for detailed analysis of key issues.
Mid-Modern Era of Agents: RAG
Checkout RAG introduction here