在多目标优化问题里,我们虽然很难确定什么是最优解,但我们可以判定什么解不是最优解. 这个想法衍生出 Pareto Optimality 做法.
Pareto Optimality
以双变量双目标优化问题为例
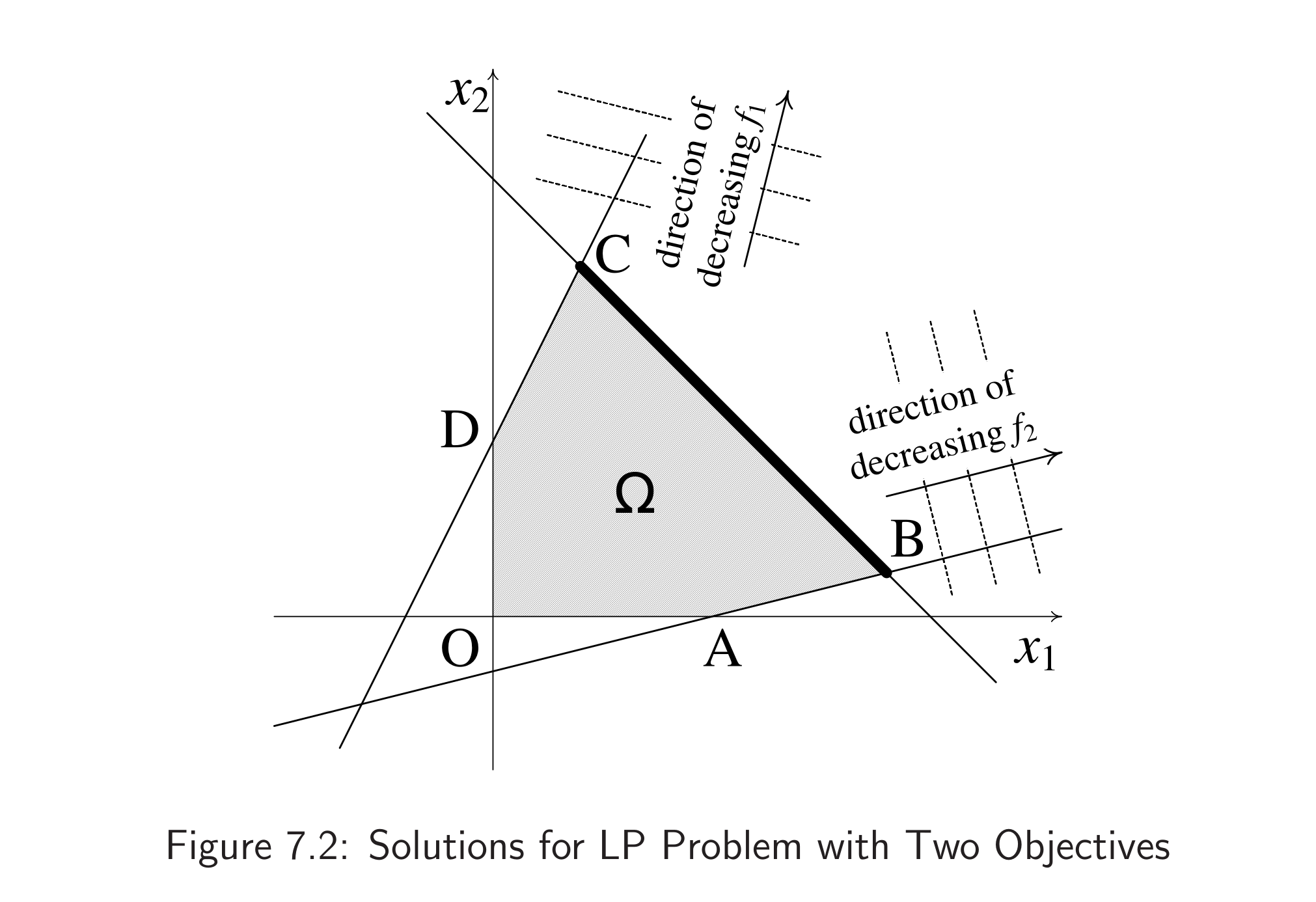
如果我们只关心
而现在,我们并不确定更关心
如果我们把坐标系换成
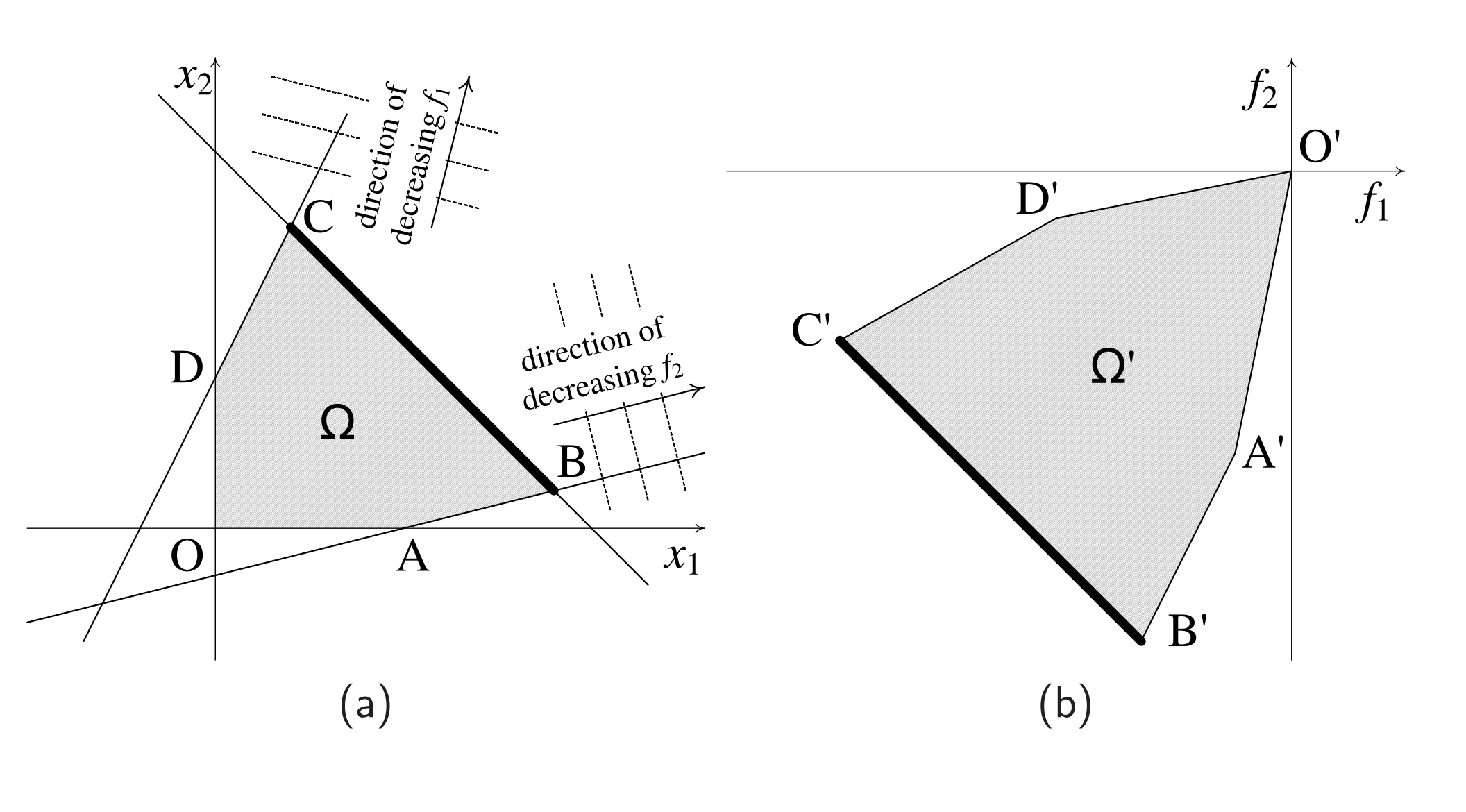
我们把上面的例子拓展到
一个解
简言之,就是不存在另外一个点,它即能保持所有其他
Generation and Visualization
那么我们怎么找这些 Pareto points 呢?一个解决办法是,多次使用
the entire Pareto frontier can theoretically be generated if the set of limits/weights can be continuously varied and the problem repeatedly solved.
但如果目标函数是 non-convex 的,那么很有可能传统方法就无法找出 pareto frontiers 了. 因为这些传统方法本质上还是只优化一个目标函数,而 pareto frontier 需要考虑多个目标函数.
所以这个时候一些遗传算法 (evolutionary techniques) 就有用武之地了. 当我们维护多个解,这意味这我们可以在一次迭代里同时优化多个目标函数.
值得注意的是,如果某些新点加入,使得原来的 pareto points 被 dominated 了,那么这些点应该被移除;而且相应的,原来的、被 dominated pareto points 所 dominate 的点可能需要重新加入集合. 基于这一观察,我们可以提出 pareto ranking scheme.
我们把最外围的 pareto points 打上 rank
,然后移除他们,在剩下的点里再找出 pareto points,打上 rank ……直到所有点都被打上了 rank. 另一个算法是,每个点的 rank
这个 rank(或者再套个函数)适合作为遗传算法里的 fitness. 如果最终的解集数量足够,并且在 objective space 里分布良好,那么我们可以从这些点里识别出 pareto frontier. 如果问题是离散的,那么 objective space 里的接近程度可能并不对应 variable space 中的接近程度.