人类穷极一切都在努力让计算机拥有人类一般的视觉能力. 然而早期的计算机只能深陷“平面”的囹圄之中:在计算机里,图像都是以矩阵、张量保存,最多编码色彩信息,而无法编码立体信息(如某个物体离我多远?).
为了克服这些问题,让计算机拥有人类一般的视觉能力,那么我们让计算机也像人类那样拥有两只“眼睛”不就好了?人类为计算机配上两个摄像机,结合数学知识,用两个摄像机模拟人类的双目视觉,让计算机也可以拥有人类一般的“深度感知”能力 (depth perception).
Stereo Vision
我们人类的双眼本质和计算机的两个摄像头没有任何区别,都是将立体的现实投影成二维的平面. 我们是怎么“感觉”到物体离我们的远近呢?
坐在运动的车内向车外看去,一般都能看到远处的物体好像运动得越慢,近处的物体好像运动得更快. 这个现象就是启发:假设车运动一秒,在我的视角下,视野内的物体会运动不同的距离,运动距离越大的物体离我越近,运动距离越小的物体离我越远.
对于静止的人眼,两眼之间的距离就是天然的“车运动一秒的距离”,所以左眼与右眼同时向前看一个物体,由于左眼与右眼不在同一个位置上(双眼之间有距离),其在左眼成像里的位置和其在右眼所成像的位置是不一样的(即前文物体运动距离的比喻). 于是,我们的大脑会自动对这两张图像进行“拟合”,把物体的位置重合.
对于计算机视觉,我们就需要将大脑的拟合过程用数学公式描述下来. 在计算机视觉里,深度 (depth) 指的就是物体到两个摄像头中心的距离,视差 (disparity, parallax) 前者指的是同一个物体在两张图像里位置的差值(后者则通常指一个现象).
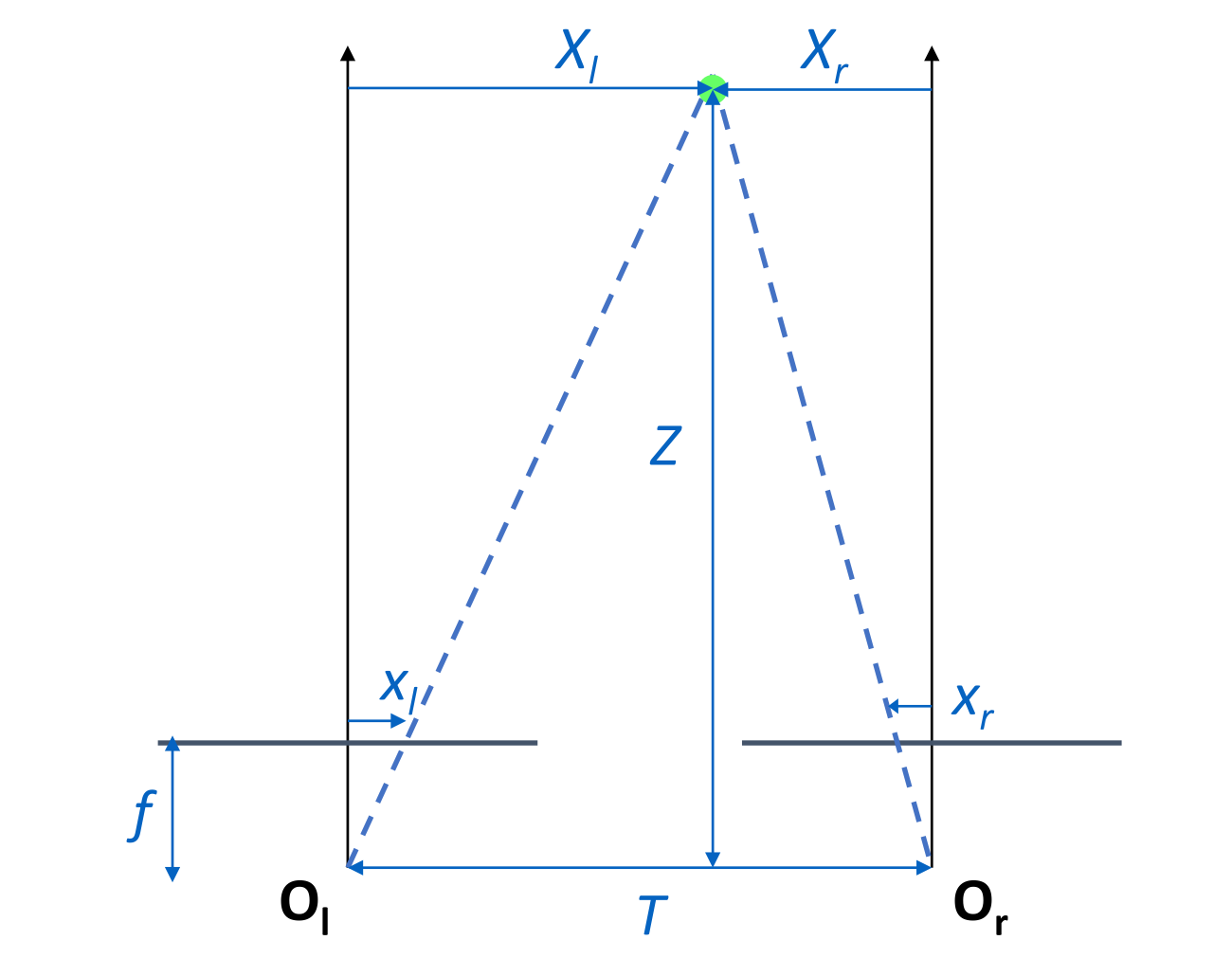
如何从视差推理深度?三角视差法
我们考虑相机之间距离为 T. 且为针孔相机,焦距为 f,物体距离相机的深度为 Z. 以下的向量中 Xl,xl>0 表示在轴的右侧,Xr,xr>0 表示在轴的左侧
从图中可知,视差(物体位置变化量)为 d=xl−xr,根据相似,有
ZXl=fxlZXr=fxr且 Xl−Xr=T. 所以
Point Matching
Point Matching 无论是 Appearance-Based 还是 Feature-Based,其核心思想都是:左右眼的图像应该相差不多,故对于左眼图像上的一个部分 Pl,在右眼图像中,我们应该可以找到一个部分 Pr^ 它和 Pl 应该是相似的.
视差图指的是对于左眼图的某个像素与右眼图里匹配的像素之间位置的差距. 即对于左眼图 Pl=(x,y),若其在右眼图的匹配为 Pr^=(x′,y′),则视差图中 D(x,y)=∥Pl−Pr^∥2
Appearance-Based Method
这个方法适用于左右眼图像形变较少的,比如说左右眼的图像的差距只有简单平移.
基于“双眼图像之间只有简单平移”的 heuristics,我们可以用一个简单的方法计算视差.
-
对于左眼图的某个像素,提取周围 h×w 的 window.
-
由于只有简单的平移,我们假设最大的位移距离为 dmax. 则我们在右眼图 x′∈[x−dmax,x+dmax],y′∈[y−dmax,y+dmax] 共计 (2dmax+1)2 个像素的这个区域里,对于 (x′,y′) 也先提取出周围 h×w 的 window,然后计算 Sum of Square Difference.
u=−⌊2h⌋∑⌊2h⌋v=⌊2w⌋∑⌊2w⌋[L(x+u,y+v)−R(x′+u,y′+v)]2
-
在右眼图区域内的所有像素里,我们令最小的 SSD 对应的那个像素 (x0′,y0′) 和 (x,y) 匹配. 即
x′,y′argminu=−⌊2h⌋∑⌊2h⌋v=⌊2w⌋∑⌊2w⌋[L(x+u,y+v)−R(x′+u,y′+v)]2
这个算法被称为 Sum of Square Difference (SSD) 算法. 这一过程的朴素实现需要使用 3 个 for 循环,我们可以用矩阵更加快速地进行实现(同时 MATLAB, Python 等的数学库对于矩阵运算都有加速支持,效率上也有提升)
矩阵加速 SSD 算法
上面算法的思路简述一下是“枚举像素找 d”. 如果可以确保只有水平移动,我们可以变换思路:枚举 d 找哪些像素的视差等于 d.
所以我们枚举视差 d,然后将右眼图向左或向右(取决于 d 的正负)平移,这样 L(x,y) 周围 h×w 的 window 和 R(x+d,y) 的 window 就对齐了. 同时 sum of square difference 可以化简为
window∑L(x,y)2+window∑R(x+d,y)2−2window∑L(x,y)R(x+d,y)前两项相当于是将 M(x,y)←M(x,y)2 后对长宽为 h×w 的 全 1 矩阵进行卷积,后面一项则是先将 L,R 两个矩阵逐元素相乘后再对全 1 矩阵进行卷积.
这样我们就对所有像素计算了在视差为 d 的情况下,像素的 SSD 值. 我们开一个大小为 H×W×dmax 的矩阵,保存下 d 时的 SSD 值. 最后再对每一个像素在 d 轴取 argmin,即可算出每一个像素的视差了.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| function [disparity] = matrix_ssd(L, R, h, w)
[H, W] = size(L);
window = ones(h, w);
maxd = 15;
costmap = inf(H, W, maxd * 2 + 1);
sqrL = conv2(L .^ 2, window, 'same');
function [mx] = rshift(mat, d)
mx = inf(size(mat));
if d >= 0
mx(:, d + 1:end) = mat(:, 1:end - d);
else
mx(:, 1:end + d) = mat(:, 1 - d:end);
end
end
for d = -maxd:maxd
Rp = rshift(R, d);
sqrR = conv2(Rp .^ 2, window, 'same');
cross = conv2(L .* Rp, window, 'same');
ssd = sqrL + sqrR - 2 * cross;
costmap(:, :, d + maxd + 1) = ssd;
end
[~, bestd] = min(costmap, [], 3);
disparity = bestd - maxd - 1;
end
|
Feature-Based Method
适用于形变较大的情况. 例如两个摄像头之间还有旋转.
Feature-Based 方法相比于 Appearance-Based 方法的区别在于几点
- Appearance-Based 使用的是左眼图像的方形区域作为 pattern 和右眼图像进行匹配;而 Feature-Based 方法则先使用 Scale Invariant Feature Transform (SIFT) 找出图像里的 feature point,然后再将其配对.
- 假设 Pl 配对上了 Pr,那么我们依然可以利用 Triangulation 计算出物体的坐标.
3D Reconstruction
相机的本质上是一个矩阵线性投影,将一个 3D 向量投影到 2D 平面上
CL=CamL:kxlkylk=a1a5a9a2a6a10a3a7a11a4a81XYZ1CR=CamR:mxrmyrm=b1b5b9b2b6b10b3b7b11b4b81XYZ1这个 3×4 的矩阵是相机的参数矩阵,如果我们可以知道这两个相机的参数矩阵,那么未知量就只有 X,Y,Z,而 xl,yl,xr,yr 也是已知的,我们就可以解出 X,Y,Z 了.
实际上,这个参数矩阵包含了四个坐标系之间的转化:世界坐标系 →(刚体变换) 相机坐标系 →(透视投影) 图像坐标系 →(二次转换) 像素坐标系. 从矩阵的角度说,包含了内参矩阵、外参矩阵、畸变参数.
我们怎么解出这个参数矩阵呢?上面的过程反过来,如果我们可以人为确定好 X,Y,Z 的坐标,然后测量 xr,yr,xl,yl 那么我们也可以反解出 CL,CR.
这个过程称为相机标定 (Camera Calibration):
- 我们固定好两个相机的位置
- 然后我们用标定板对相机进行标定. 因为使用了标定板,所以三维坐标可以认为是已知的. 进而反解出参数矩阵.
然后就可以利用视差进行 3D 重建了.
通过列方程,我们最后可以得到这样的方程
a9xl−a1a9yl−a5b9xr−b1b9yr−b5a10xl−a2a10yl−a6b10xr−b2b10yr−b6a11xl−a3a11yl−a7b11xr−b3b11yr−b7XYZ= a4−xla8−ylb4−xrb8−yr记左侧 4×3 的矩阵为 W,右侧的四维向量为 q. 我们可以用 pseudo-inverse 解出 X,Y,Z 的值:
XYZ=W+q=(W⊤W)−1W⊤q
Deep Stereo Vision
这一部分介绍一点时间稍微早一点的工作,用深度学习解决立体视觉的问题.