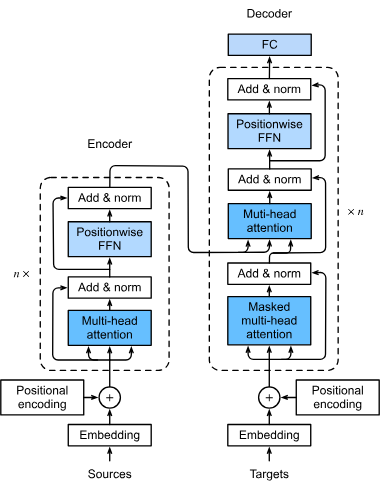
从整体的架构来看,Transformer 由 Encoder 和 Decoder 两个部分组成.
对于输入数据 x \bold{x} x x ′ ← x + P ( x ) \bold{x}'\gets \bold{x}+\bold{P}(\bold{x}) x ′ ← x + P ( x )
紧接着,张量 x ′ \bold{x}' x ′ 多个 stacked layers ,每一个 layer 包含两个 sublayers:
首先经过 Multi-Head Self Attention 以及 Residual Connection & Layer Norm
其次经过 Fully Connected Network (FCN) 以及 Residual Connection & Layer Norm
我们设计了 Add and Layer Normalization,所以,我们的 FCN 和 Attention 输出的词向量维度应该和输入词向量维度一致,即 x ∈ R d \bold{x}\in\R^d x ∈ R d x + sublayer ( x ) ∈ R d \bold{x}+\text{sublayer}(\bold{x})\in\R^d x + sublayer ( x ) ∈ R d
于是,Transformer 的 Encoder 为句子里的每一个位置输出一个 d d d
Transformer Decoder 部分也是 stack of layers. 同样,在 embedding 完后,我们先做一次 Positional Encoding. 然后依次经过
Masked Multi-Head Self Attention, Residual Connection & Layer Norm
这里为什么是 Masked 呢?这与 Transformer 生成答案的过程有关.
我们知道,Transformer 在生成 token 的时候是 autoregressive 的,即生成第 i i i i + 1 → ∞ i+1\to\infin i + 1 → ∞ 1 → i − 1 1\to i-1 1 → i − 1 i + 1 → ∞ i+1\to \infin i + 1 → ∞ 0 0 0
Encoder-Decoder Multi-Head Attention, Residual Connection & Layer Norm
这里的特殊之处在于,Query 是上一层 Masked Multi-Head Self Attention 的输出,KV 则是来自 Encoder 的输出.
其意义(感性地理解)差不多是,我们已经知道了目标语言的句子的关联,现在是时候把目标语言的单词和源语言的单词一一对应起来了.
Pointwise FFN, Residual Connection & Layer Norm
Pointwise FFN 将所有句子的单词的词向量表示进行 transformation. 其实就是线性层 + ReLU + 线性层
实现起来也不算很难.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import torchimport torch.nn as nnfrom typing_extensions import Optional class PositionWiseFFN (nn.Module): def __init__ (self, ffn_hidden_dims: int , ffn_output_dims: int ): super ().__init__() self .dense1 = nn.LazyLinear(ffn_hidden_dims) self .relu = nn.ReLU() self .dense2 = nn.LazyLinear(ffn_output_dims) def forward (self, X: torch.Tensor ) -> torch.Tensor: return self .dense2(self .relu(self .dense1(X)))
下面的 X \tt{X} X Y \tt Y Y
1 2 3 4 5 6 7 8 9 class AddNorm (nn.Module): def __init__ (self, dim, dropout ): super ().__init__() self .dropout = nn.Dropout(dropout) self .ln = nn.LayerNorm(dim) def forward (self, X, Y ): return self .ln(self .dropout(Y) + X)
我们先编写单个 Encoder Block,其包含两个 sublayers
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class EncoderBlock (nn.Module): def __init__ ( self, num_hidden: int , ffn_dim: int , num_heads: int , dropout: float = 0.5 , ): super ().__init__() self .attention = MultiHeadAttention(num_hidden, num_heads, dropout) self .addnorm1 = AddNorm(num_hidden, dropout) self .ffn = PositionWiseFFN(ffn_dim, num_hidden) self .addnorm2 = AddNorm(num_hidden, dropout) def forward ( self, X: torch.Tensor, valid_lens: Optional [torch.Tensor] = None , ) -> torch.Tensor: Y = self .addnorm1(X, self .attention(X, X, X, valid_lens)) return self .addnorm2(Y, self .ffn(Y))
然后就可以来实现 Encoder 了.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Encoder (nn.Module): def __init__ ( self, vocab_size: int , num_hidden: int , ffn_dim: int , num_heads: int , num_blocks: int , dropout: float , use_bias: bool = False , ): super ().__init__() self .num_hidden = num_hidden self .embedding = nn.Embedding(vocab_size, num_hidden) self .pos_emb = PositionalEncoding(num_hidden, dropout) self .blocks = nn.Sequential() for i in range (num_blocks): self .blocks.add_module( f"block_{i} " , EncoderBlock(num_hidden, ffn_dim, num_heads, dropout), ) def forward ( self, X: torch.Tensor, valid_lens: Optional [torch.Tensor] = None , ) -> torch.Tensor: X = self .embedding(X) X = self .pos_emb(X * math.sqrt(self .num_hidden)) self .attn_weights = [] for i, block in enumerate (self .blocks): X = block(X, valid_lens) self .attn_weights.append(block.attention.attention.attn_weights) return X
d \sqrt{d} d
这是因为 nn.Embedding 的权重都是随机初始化的,如果使用 Xavier 初始化,则参数服从 W i j ∼ N ( 0 , 1 d ) W_{ij}\sim \mathcal{N}(0, \frac{1}{d}) W ij ∼ N ( 0 , d 1 )
而在 Positional Encoding 里面,cos , sin \cos, \sin cos , sin [ − 1 , 1 ] [-1,1] [ − 1 , 1 ] nn.Embedding 的值过小,那么相加后,结果将由 Positional Encoding 主导. 几乎相当于是原句子全部被舍弃,只有位置信息在参与后续的意义关联(
所以,我们需要人为地提升 embedding 的值的 scaling,故我们 × d \times \sqrt{d} × d Var = 1 \text{Var}=1 Var = 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 class DecoderBlock (nn.Module): def __init__ ( self, num_hiddens: int , ffn_dim: int , num_heads: int , dropout: float , i: int , ): super ().__init__() self .i = i self .attn1 = MultiHeadAttention(num_hiddens, num_heads, dropout) self .addnorm1 = AddNorm(num_hiddens, dropout) self .attn2 = MultiHeadAttention(num_hiddens, num_heads, dropout) self .addnorm2 = AddNorm(num_hiddens, dropout) self .ffn = PositionWiseFFN(ffn_dim, num_hiddens) self .addnorm3 = AddNorm(num_hiddens, dropout) def forward ( self, X: torch.Tensor, state: tuple [torch.Tensor, torch.Tensor, Dict ], ) -> tuple [torch.Tensor, tuple ]: """State 就是从 Encoder 传过来的 context & valid_lens.""" enc_output, enc_valid_lens = state[0 ], state[1 ] if state[2 ][self .i] is None : key_values = X else : key_values = torch.cat((state[2 ][self .i], X), dim=1 ) state[2 ][self .i] = key_values if self .training: batch, num_steps, dim = X.shape decoder_visible_mask = torch.arange( 1 , num_steps + 1 , device=X.device, ).repeat(batch, 1 ) else : decoder_visible_mask = None X2 = self .attn1(X, key_values, key_values, decoder_visible_mask) Y = self .addnorm1(X, X2) Y2 = self .attn2(Y, enc_output, enc_output, enc_valid_lens) Z = self .addnorm2(Y, Y2) return self .addnorm3(Z, self .ffn(Z)), state
这一段代码的 __init__() 还是比较易懂的,基本上就是和之前的结构图对应上了.
然而在 forward() 里面有点细节。首先 s t a t e \tt state state
state 0 \texttt {state}_0 state 0 state 1 \texttt{state}_1 state 1 state 2 \texttt{state}_2 state 2
首先读这一段代码:训练时,一次性输入一整串目标序列,所以 state 直接保存完整序列;而在推理的时候,每一步都会新增一个 token,于是用 torch.cat 拼接起来
1 2 3 4 5 if state[2 ][self .i] is None : key_values = X else : key_values = torch.cat((state[2 ][self .i], X), dim=1 ) state[2 ][self .i] = key_values
接下来看这段代码:如果是训练,那么我们需要构造严格的 masking 让 t t t t + 1 → ∞ t+1\to \infin t + 1 → ∞
1 2 3 4 5 6 7 8 9 if self .training: batch, num_steps, dim = X.shape decoder_visible_mask = torch.arange( 1 , num_steps + 1 , device=X.device, ).repeat(batch, 1 ) else : decoder_visible_mask = None