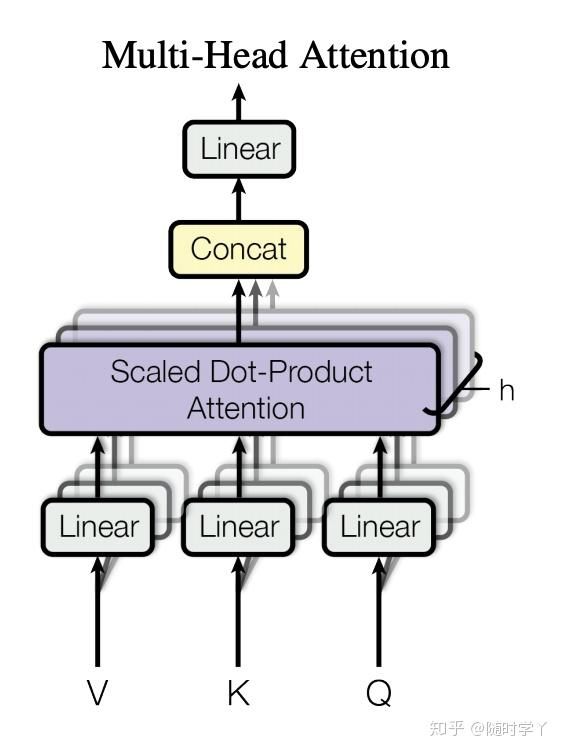
Multi Head Attention
大多数时候,我们希望模型能够从相同的输入里面学到不同的东西(或者说,能学到不同方面的东西). 而如果只有一个 Attention 模块,很显然不论怎么学,模型最终只能学习到一个概率分布. 所以为了改进这一点,我们引入 Multi-Head Attention
每一个 Attention 的输出称为 Head,所以我们有很多的 Attention Head,假定我们有 h 个 Attention Head. 对于输入的 Q,K,V,我们先用 h 个 Fully Connected Layer 分别 transform Q,K,V 得到 Qi,Ki,Vi. 然后分别输入 h 个 Attention Head. 最后,将这 h 个 Attention Head 的 Output 拼接起来,再最后经过一次 Fully Connected Layer.
用数学语言描述的话就是,令 Q∈Rdq,K∈Rdk,V∈Rdv,单个 Attention Head 的数学描述为
hi=Attn(Wi(q)Q,Wi(k)K,Wi(v)V)∈Rpv其中 pv 为 Attention Head 的输出维度,Wi(q)∈Rpq×dq,Wi(k)∈Rpk×dk,Wi(v)∈Rpv×dv. 最后,我们还会接上一个 Fully Connected Layer Wo
Woh1h2⋮hh∈Rpo
进一步解释
我们的 Multi Head Attention 的流程如下.
首先输入三个三维张量 Q,K,V. 此时,这三个张量分别有各自的 batch size b、包含的 token 数量 n、token 的 embedding vector 的维度 d(我们这里把 embedding vector 理解为包含其语义信息).
现在,假设我们的 Attention 模块处理的词向量空间的维度为 hidden dimension D,并且包含 h 个 Attention Head.
那么很显然,第一步,我们先需要把三个张量的词向量维度都先投影到统一的 Attention Space 里,这样才能让 Query 对应的 K-V 加权和更加 make sense. 即,使用 3 个 nn.Linear.
1
2
3
4
5
6
7
8
9
10
11
|
self.Wq = nn.LazyLinear(D)
self.Wk = nn.LazyLinear(D)
self.Wv = nn.LazyLinear(D)
Q = self.Wq(Q)
K = self.Wk(K)
V = self.Wv(V)
|
接着,我们需要让每一个 Head 处理词向量维度的一部分,注意这里是词向量维度而不是 token 数量维度!
我们可以这么理解:我们希望每一个 Attention Head 学习到的是不同 token 之间不同领域的管理。关键点在于不同领域,如果按照 token 数量进行切分,那么实际上变成了每个 Head 学习句子局部之间的关系,这肯定就不对了。所以这一段对应的张量操作,其实是把最后一维 (D,) 进一步拆分成 (h,hD).
1
2
3
4
5
6
7
8
9
10
11
12
| def transpose_qkv(self, x: torch.Tensor):
x = rearrange(
x,
"batch seq (heads eachhead) -> batch seq heads eachhead",
heads=self.num_heads,
)
return x
Q = self.transpose_qkv(Q)
K = self.transpose_qkv(K)
V = self.transpose_qkv(V)
|
对 Q,K,V 都做完 transpose_qkv(),我们接下来就想像 normal Attention 那样:对于每一个 batch,其中对于每一个 head,对 Q 的 nq 个 token 计算 nk 个 score,然后再对 V 求加权和。从张量形状的角度来看,这个变化过程为
(b,nq,h,hD) @ (b,nk,h,hD)⟹(b,nq,h,nk)这个需求其实和 torch.bmm:Rn×m×ℓ @ Rn×ℓ×p↦Rn×m×p 很像. 然而 torch.bmm() 只接受三维的张量. 所以,我们考虑把 b,h 这两个维度压缩到一起(反正他们在过程中是不会变的),然后执行 torch.bmm()
这里,注意到把 b,h 两个维度压缩到一起后,其实和 "batch"×#words×#dim 的形式已经差不多了,所以这里可以直接套用 normal Attention 的实现. 最后再把结果的形状转回去即可.
1
2
3
4
5
6
7
8
9
10
11
| def tf(self, x: torch.Tensor):
return rearrange(
x,
"batch seq heads eachhead -> (batch heads) seq eachhead",
)
Q = self.tf(Q)
K = self.tf(K)
V = self.tf(V)
output = self.attention(Q, K, V)
|
于是乎得到的张量形状是
(bh,nq,hD)再用 rearrange 把它变回 (b,nq,h×hD),最后再套一层线性层 Wo 即可
1
2
3
4
5
6
7
| output = rearrange(
output,
"(batch heads) numq eachhead -> batch numq (heads eachhead)"
)
output = self.Wo(output)
return output
|